drf框架学习分享
django rest framework-一个基于Django的REST框架,用于构建Web API
接下来我会分享关于我在学习drf过程中的一些心得体会,以及一些遇到的问题和解决方法。
FBV&CBV
fbv-function base view
要通过手动的方式对不同的请求方式进行处理
cbv-class base view
django原生cbv: 通过继承View类,调用View中的dispatch实现不同请求方式的路由
基于drf的cbv:
request对象
drf中的request不是原生的,它对python中原有的request进行了封装,封装了request.data,request.query_params等属性,方便我们使用。
但是可以通过drf中的request.xxx(相当于request._request.xxx)获取到python中的request.xxx属性。因为drf中通过getattr,__getattr__, __getattribute__方法,使得这些查找参数的过程对我们透明了。
查找的逻辑是: 先在本对象找该参数,如果找不到,则去原生request中找,如果找不到,则报错
def __getattr__(self, attr):
"""
If an attribute does not exist on this instance, then we also attempt
to proxy it to the underlying HttpRequest object.
"""
try:
return getattr(self._request, attr)
except AttributeError:
return self.__getattribute__(attr)
getattr,__getattr__, __getattribute__和__get__的区别
https://zhuanlan.zhihu.com/p/67586184 这个页面是关于Python中的几个常用的方法和函数,它们的作用和区别。页面的主要内容如下:
getattr()函数:这是一个内置的函数,可以用来获取对象的属性和方法。
如果对象不存在该属性,可以设置一个默认值,否则会报错。
- __getattr()__和__getattribute__()魔法方法:这两个方法是在访问对象属性时被调用的。
__getattribute__()方法总是会被调用,无论属性是否存在。如果属性不存在,就会调用__getattr__()方法,可以在这个方法里设置属性不存在时的默认值。
- get()方法:这是一个描述符方法,可以将访问对象属性转变为调用描述符方法。描述符可以在获取或者给对象赋值时对数据值进行一些特殊的加工和处理。@property装饰器就是通过描述符的方式实现的。描述符分为数据描述符和非数据描述符,区别在于是否实现了__set__()或__del__()方法。
类对象的魔法函数
Python中的类对象有很多魔法函数,它们是以双下划线开头和结尾的特殊方法。这些魔法函数可以让我们在类中自定义函数,并绑定到类的特殊方法中。这样,我们就可以在类的实例化对象上调用这些函数,从而实现一些特殊的功能。
以下是一些常见的类对象魔法函数:
__init__():构造函数,用于初始化对象的属性。__str__():返回对象的字符串表示形式。__new__():创建对象并返回它。__unicode__():返回对象的Unicode字符串表示形式。__call__():使对象可以像函数一样被调用。__len__():返回对象的长度。__repr__():返回对象的字符串表示形式,通常用于调试。__setattr__():设置对象的属性。__getattr__():获取对象的属性。__getattribute__():获取对象的属性,与__getattr__()不同的是,它会在任何情况下都被调用。__delattr__():删除对象的属性。__setitem__():设置对象的索引值。__getitem__():获取对象的索引值。__delitem__():删除对象的索引值。__iter__():返回一个迭代器。__del__():析构函数,用于释放对象占用的资源。__dir__():返回对象的属性列表。__dict__():返回对象的属性字典。
以上是一些常见的类对象魔法函数
类的魔法函数与类的普通函数的区别
Python中的类有许多特殊的函数,也称为魔法函数。这些函数的名称以双下划线开头和结尾,例如__init__和__str__。这些函数与普通函数的区别在于,它们是类的特殊方法,可以在类中自定义函数并绑定到这些方法中。这些函数的调用方式也不同于普通函数,它们会在特定的情况下自动调用。例如,__init__函数是类的构造函数,用于初始化新创建的对象。当创建一个新的类实例时,__init__函数会自动调用。相反,普通函数需要显式调用才能执行。
另一个区别是,魔法函数可以让类增加一些额外的功能,方便使用者理解。例如,__str__函数可以让类的实例以字符串的形式输出,而不是默认的对象表示形式。这些函数的具体作用取决于它们的名称和用途,但它们都是用于增强类的功能和灵活性的。
希望这可以帮助您更好地理解Python中类的魔法函数和普通函数之间的区别。
类对象和实例对象
类对象和实例对象是Python中的两个重要概念。类对象是指在Python中定义的类,它是一个抽象的模板,用于创建具有相同属性和行为的多个对象。而实例对象则是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。例如,我们可以定义一个名为Student的类,然后创建多个不同的Student实例对象,每个实例对象都有自己的属性和方法。类对象和实例对象之间的主要区别在于,类对象是抽象的,而实例对象是具体的。如果你想了解更多关于类对象和实例对象的信息,可以参考这篇知乎文章²。
反射
在Python中,反射是指在运行时通过字符串的形式来访问、调用、修改或创建对象、模块、函数、类等的属性和方法的能力。反射使得我们可以根据程序运行时的状态来动态地操作对象,而不需要事先编写固定的代码。
Python中的反射主要借助于以下几个内置函数和特殊方法:
getattr(object, name[, default]):用于获取对象的属性或方法。参数object是待操作的对象,name是属性或方法的名称,default是可选参数,表示如果属性或方法不存在时返回的默认值。
setattr(object, name, value):用于设置对象的属性或方法。参数object是待操作的对象,name是属性或方法的名称,value是要设置的值。
hasattr(object, name):用于判断对象是否具有指定的属性或方法。参数object是待操作的对象,name是属性或方法的名称。
delattr(object, name):用于删除对象的属性或方法。参数object是待操作的对象,name是属性或方法的名称。
__dict__:是一个特殊的字典属性,包含了对象的所有属性和方法。可以通过字典的方式操作这些属性和方法。
反射的使用可以在很多场景中发挥作用,比如动态地调用函数、根据用户输入执行不同的方法、动态地创建类或对象等。但需要注意,由于反射是基于字符串的,因此在使用时要注意安全性和错误处理,避免操控不当导致意外的结果。
在Python中,反射是指通过字符串来访问对象的属性和方法。通常情况下,我们会直接使用对象的属性或方法,比如obj.attribute或obj.method()。但是有时我们需要根据运行时的情况动态地访问对象,而不是提前知道需要访问的属性或方法的名称。
反射提供了一种灵活的方式来实现这个目的。我们可以通过字符串来获取对象的属性或方法,而不需要直接使用属性或方法的名称。这使得我们可以在运行时根据需要进行操作,而不需要提前定义所有的属性和方法。
举个例子,假设我们有一个叫obj的对象,并且我们希望通过字符串获取该对象的属性或方法,我们可以使用getattr(obj, 'attribute')来获取属性的值,或者使用getattr(obj, 'method')()来调用方法。
反射的应用场景很广泛,可以实现动态加载模块、调用不同的函数、动态调整对象的属性等等。通过反射,我们可以根据需要在运行时决定对象的行为,增加了程序的灵活性和动态性。但是需要注意的是,在使用反射时要谨慎,确保操作的安全性,并进行适当的错误处理。
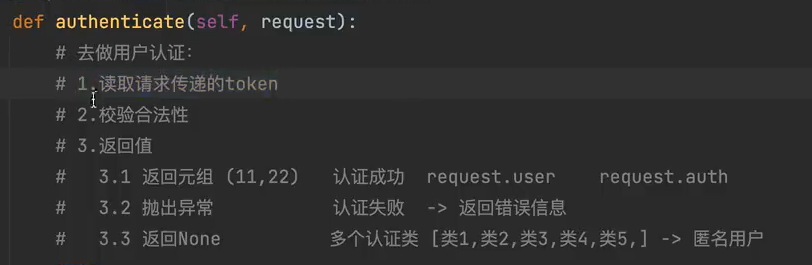
认证组件

-
局部配置
在要配置认证组件的视图函数中,通过
authentication_classes = []添加验证器 -
全局配置
在settings.py的REST_FRAMEWORK中配置
DEFAULT_AUTHENTICATION_CLASSES3. 配置的优先级遵从就近原则 4. !注意! 认证组件为全局引用时不能写在view视图中,会出现循环引用的问题 5. 加载认证组件,本质就是实例化每个认证类的对象,并封装到request对象 6. 针对面向对象中的继承这一特性,调用self属性时,应该先明确self是哪个类的对象,先从实例化的类中找,找不到再从父类中找 7. 多个认证类都返回None,都没有认证成功->视图是否会被执行?视图函数会执行,只不过 self.user,self.auth = None 8. raise抛出异常,向上抛,向调用它的地方抛,没人捕获他就继续向上抛 认证组件中的认证类配置同理 9. 返回状态码一致性
在认证类中需要配置
authenticate_header方法,不然返回的状态码始终为403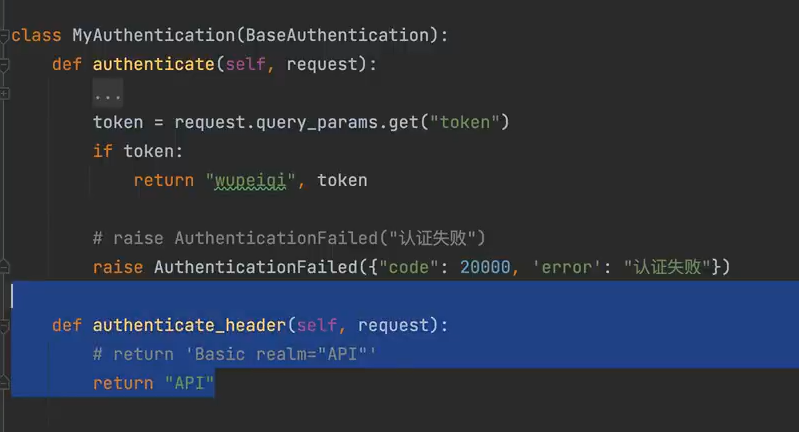 10. 扩展,python开发常见。子类约束
10. 扩展,python开发常见。子类约束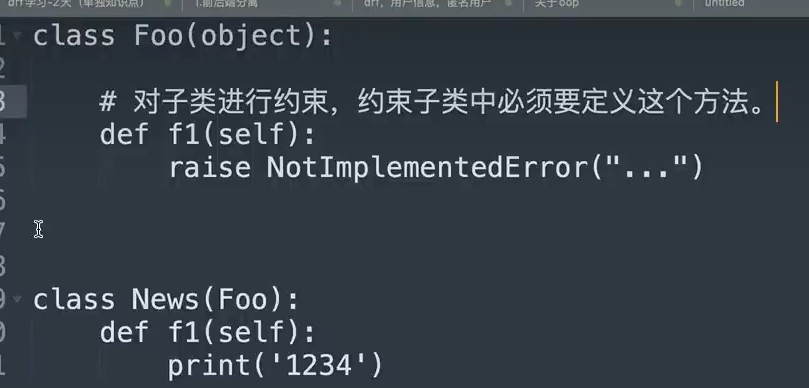 像是java中的接口、抽象类和抽象方法
像是java中的接口、抽象类和抽象方法权限组件
 1. 认证组件是或的关系。权限组件,链式执行,全部通过才是通过
2. 自定义权限组件认证失败错误信息
- 在权限类中配置message变量
3. 自定义权限验证逻辑
- 重写
1. 认证组件是或的关系。权限组件,链式执行,全部通过才是通过
2. 自定义权限组件认证失败错误信息
- 在权限类中配置message变量
3. 自定义权限验证逻辑
- 重写has_permission方法 4. 1. 思考1
- 当想要替换原生组件时,首先去判断它是什么时候创建的,可不可以把创建的这个位置的类替换
- 接下来再分析流程
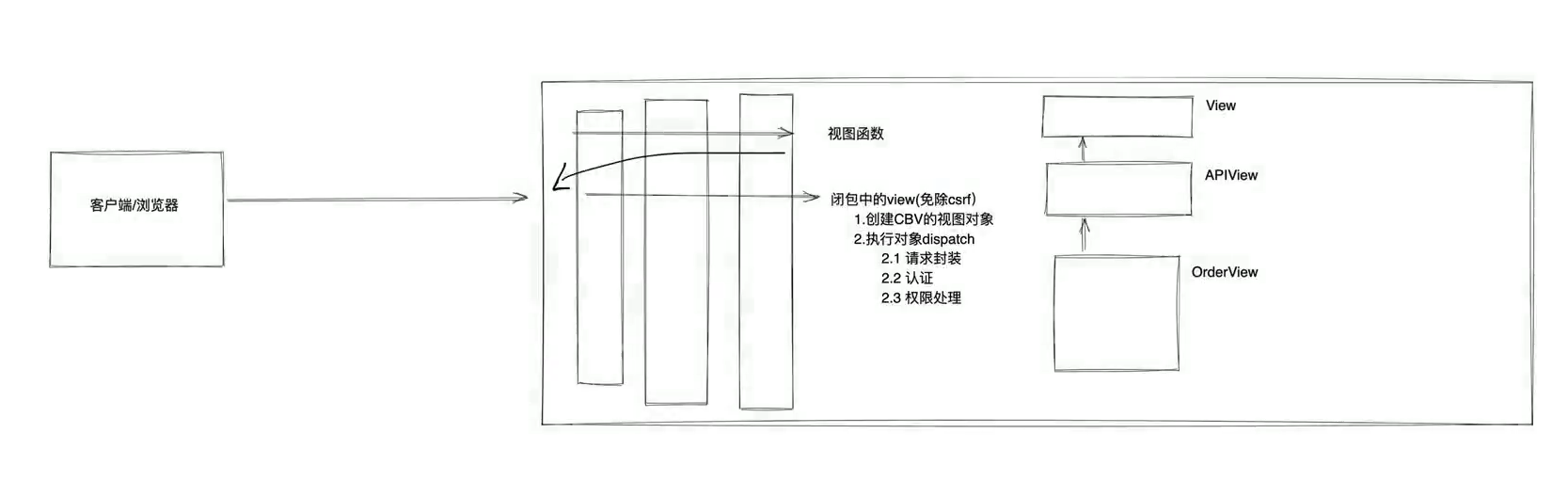
1. 思考2
- 通过组建的生命周期来分析它们的关系
-
1. 思考1
- 当想要替换原生组件时,首先去判断它是什么时候创建的,可不可以把创建的这个位置的类替换
- 接下来再分析流程
1. 思考2
- 通过组建的生命周期来分析它们的关系
- 
限流组件
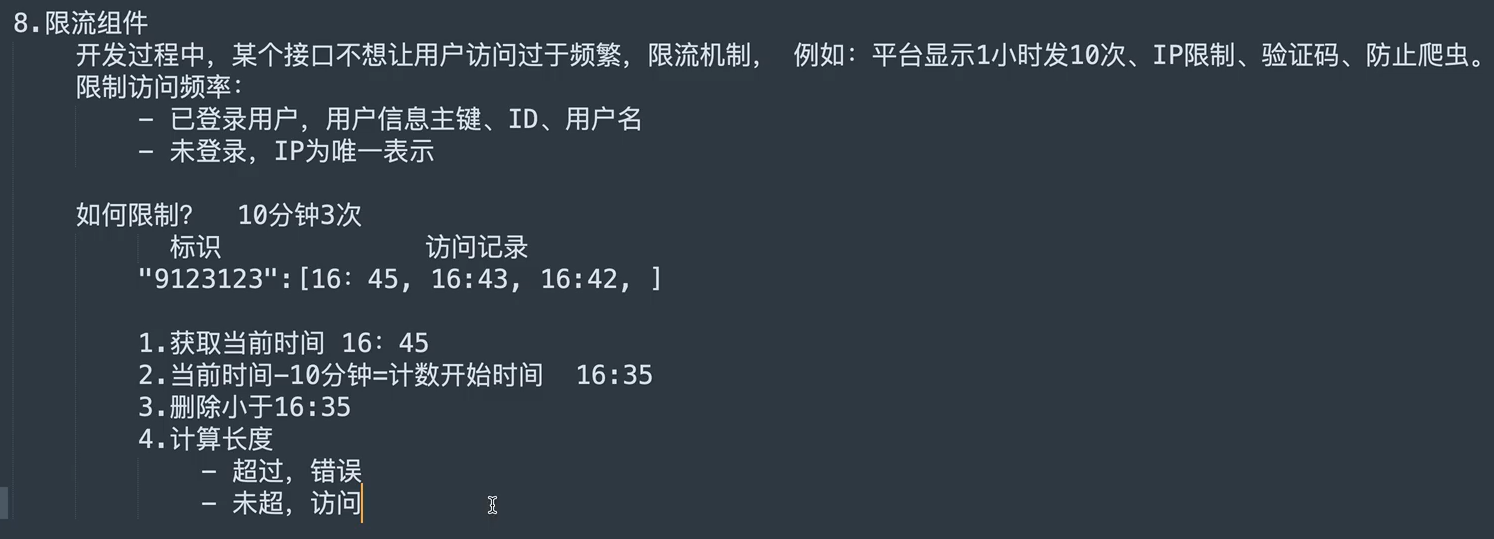




day14
版本组件
- 基于get参数
- 使用
QueryParameterVersioning作为版本类 - 对视图类配置
versioning_class参数为类引入版本组件 - 可以通过在settings.py配置
VERSION_PARAM参数自定义在请求参数中代表版本的key名 - 通过配置settings.py可以配置默认版本号、允许版本号
- 反向生成url
- 通过
request.versioning_scheme.reverse反向生成url - 相比django原生的reverse,versioning_reverse可以生成版本号,会自动生成版本信息
- 反向生成url时,只能生成url格式一样的同一类url,组织形式不一样的url无法生成
- 通过
- 基于路由url
- 使用
URLPathVersioning作为版本类 - 修改路由path,在其中加上
version参数,传递到视图类后可以通过版本组件方便的获取版本信息 - 基于accept请求头
- 使用
AcceptVersioning作为版本类 - 修改请求头,在请求头中增加
version参数,传递到视图类后可以通过版本组件方便的获取版本信息 - 通过在settings.py配置
DEFAULT_VERSIONING_CLASS参数可以设置默认版本类
解析器
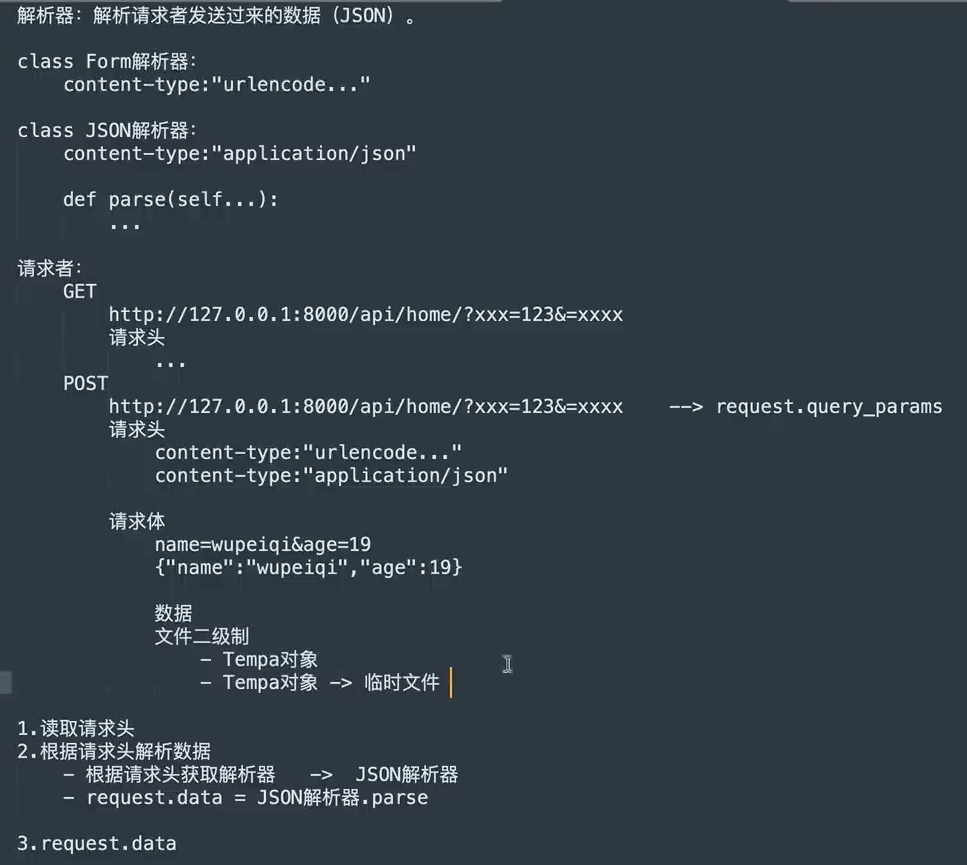 1. 用于解析请求者发过来的数据(JSON等)
2. 主要针对请求体进行解析,请求头中的数据已经被
1. 用于解析请求者发过来的数据(JSON等)
2. 主要针对请求体进行解析,请求头中的数据已经被request.queryparam读取走了
3. parser_classes配置应用的所有解析器,content_negotiation_class根据请求调用对应解析器
4. 所有数据都会存到request中,但不会进行解析,调用request.data获取解析后的数据,同一个request只加载一次,再次调用直接去full_data中拿
5. 文件解析器
- fileUploadParser只能上传文件
- MultiPartParser可以上传文件和数据
6. 当不配置解析器时,系统默认的解析器是fileUploadParser之外的三个。通过配置DEFAULT_PARSER_CLASSES可以修改默认解析器
元类
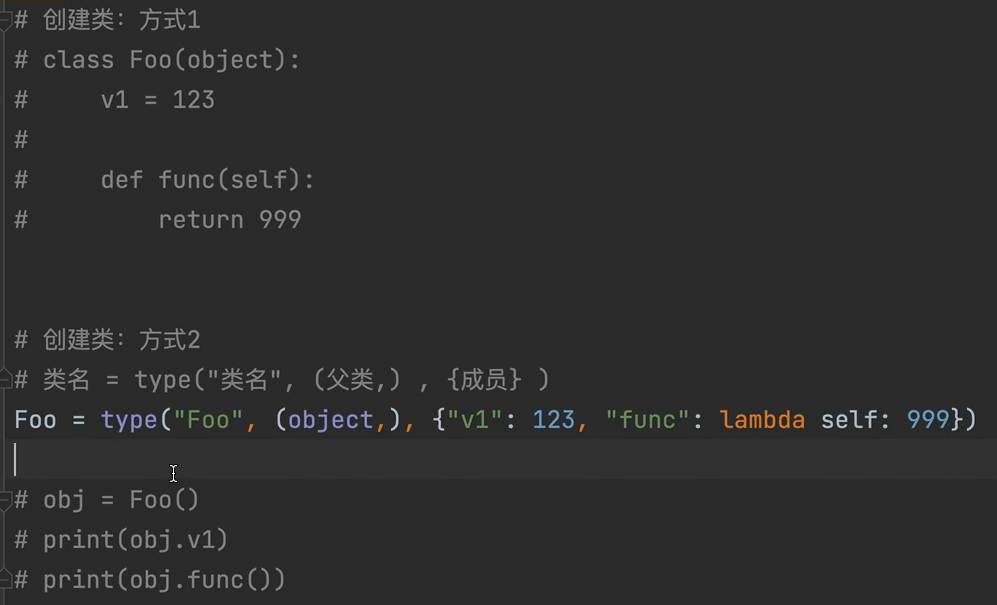
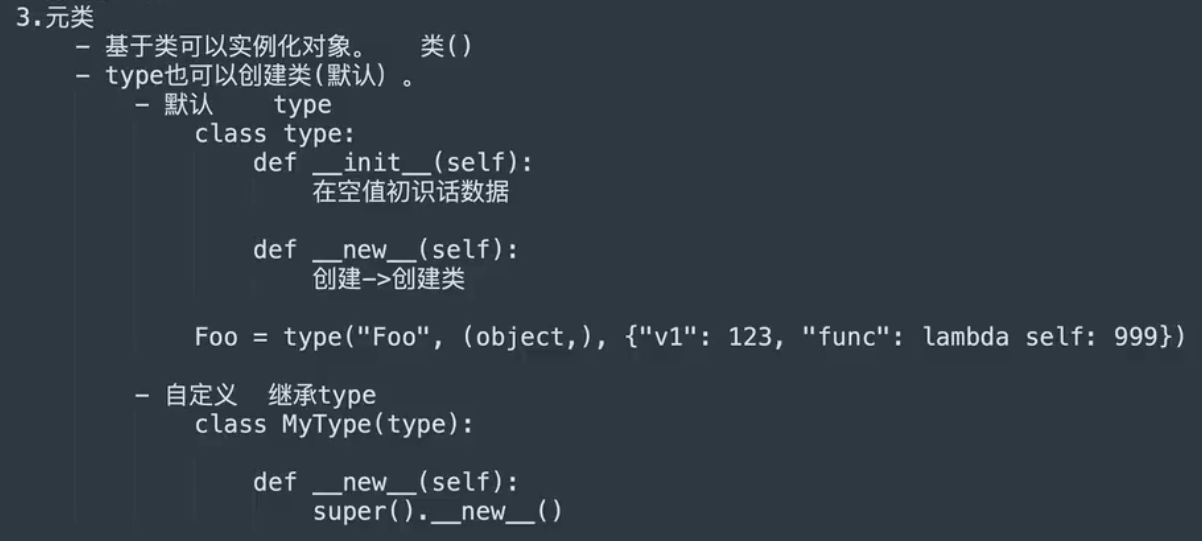
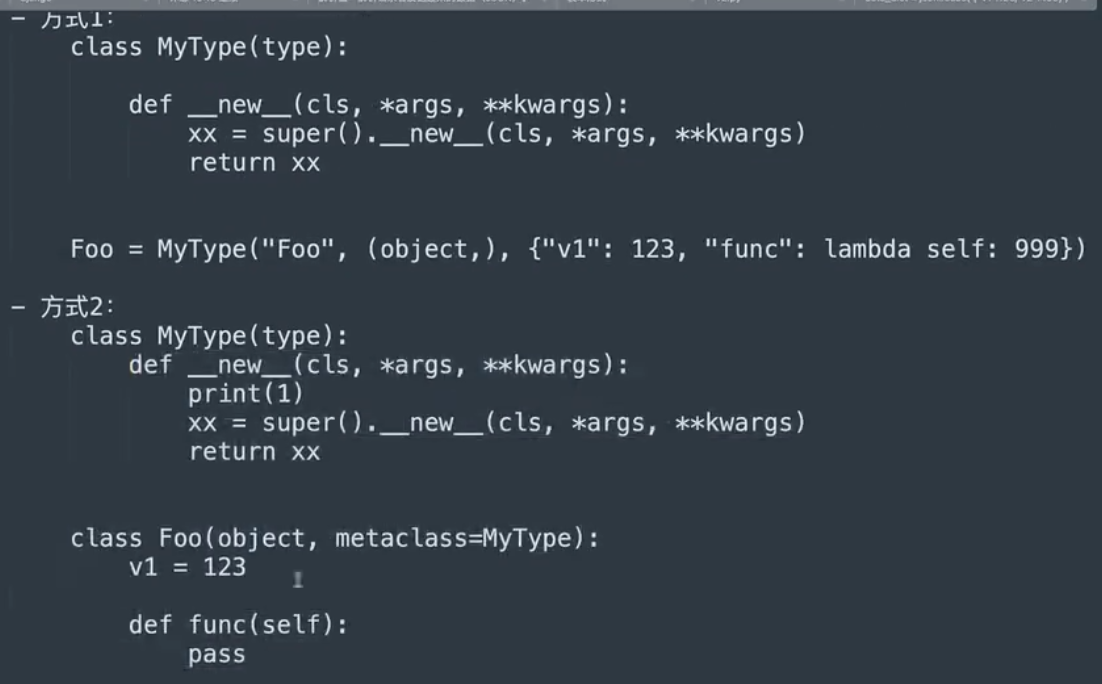
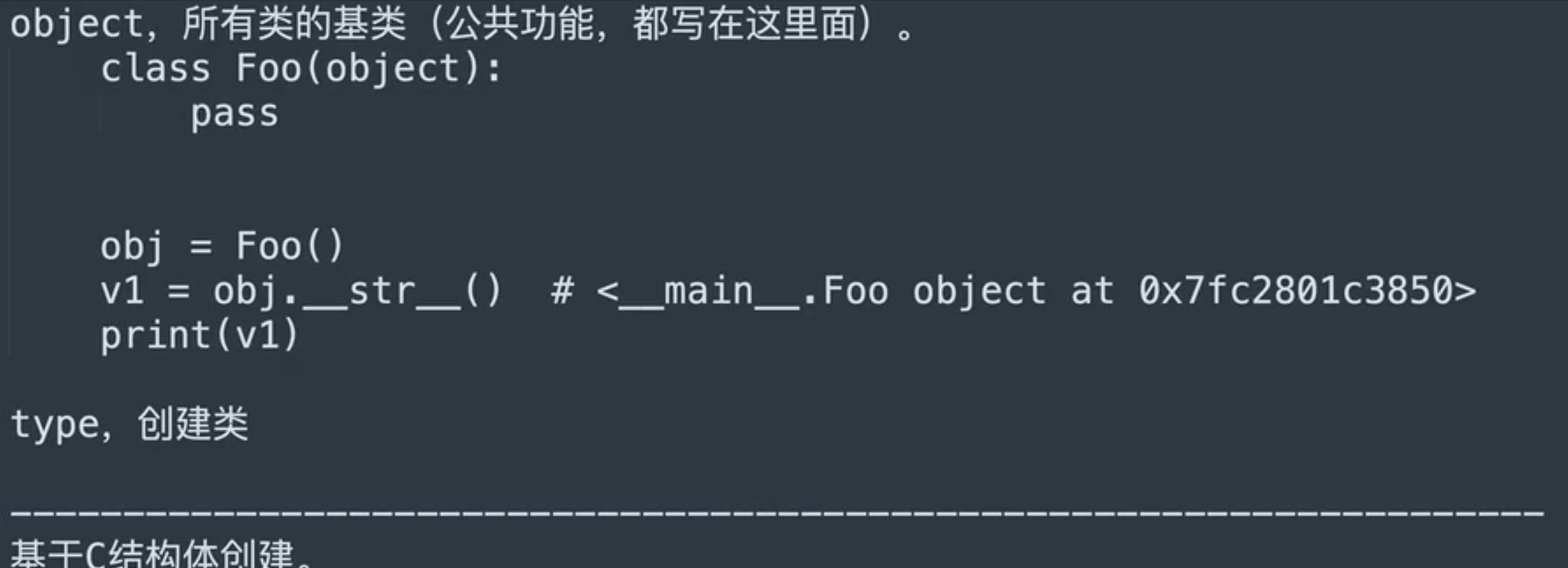
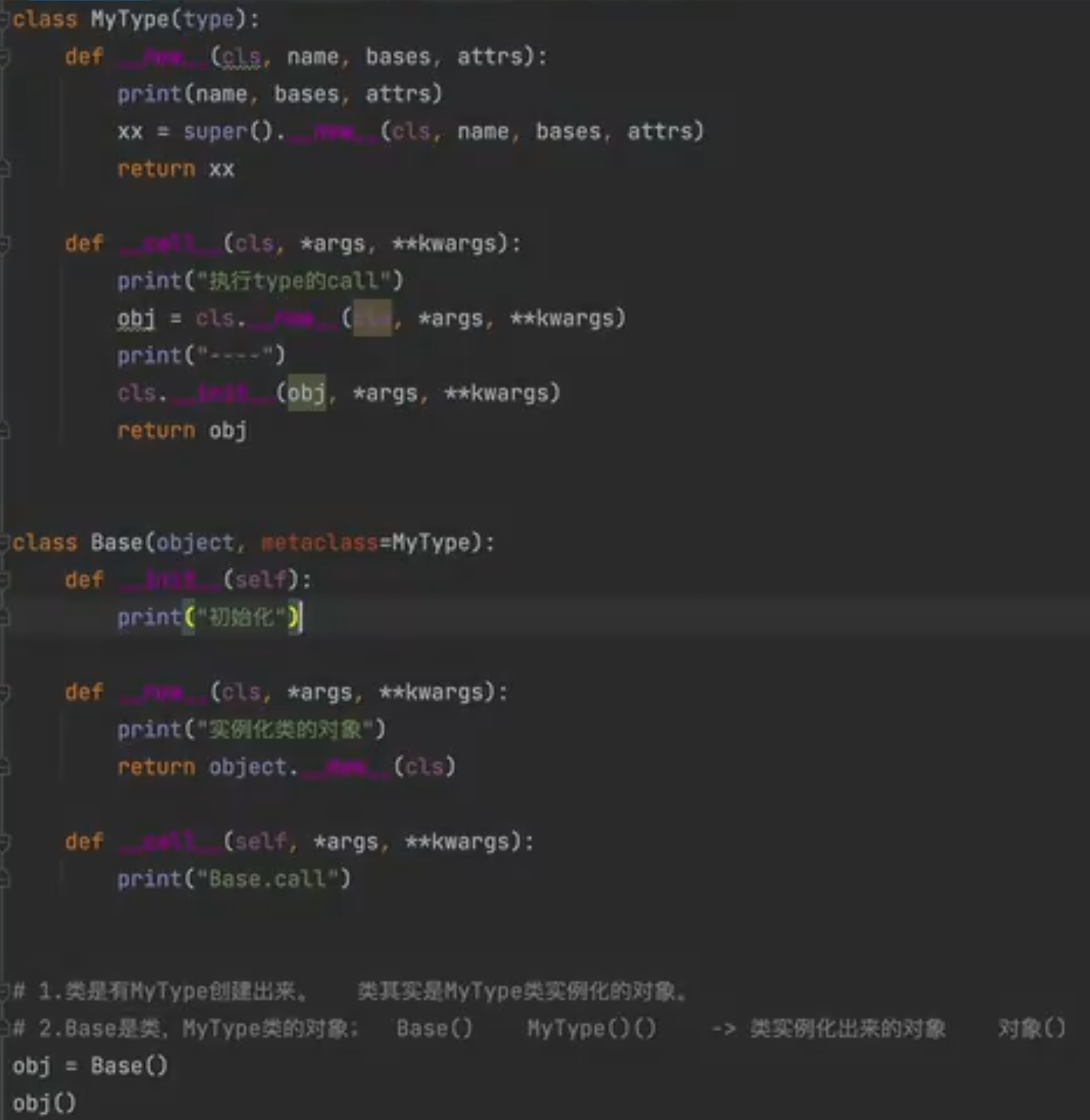
 - 两种创建类的方式,底层都是通过调用type类中的
- 两种创建类的方式,底层都是通过调用type类中的new()函数创建类,再调用init()方法对类进行初始化
- 创建和初始化的操作都是通过调用type类的call()方法来触发的
- 通过向类传入metaclass参数可以指定元类
- 关于子类
- 类中获取父类中指定了metaclass,全部都是由metaclass创建的类
序列化器(*)
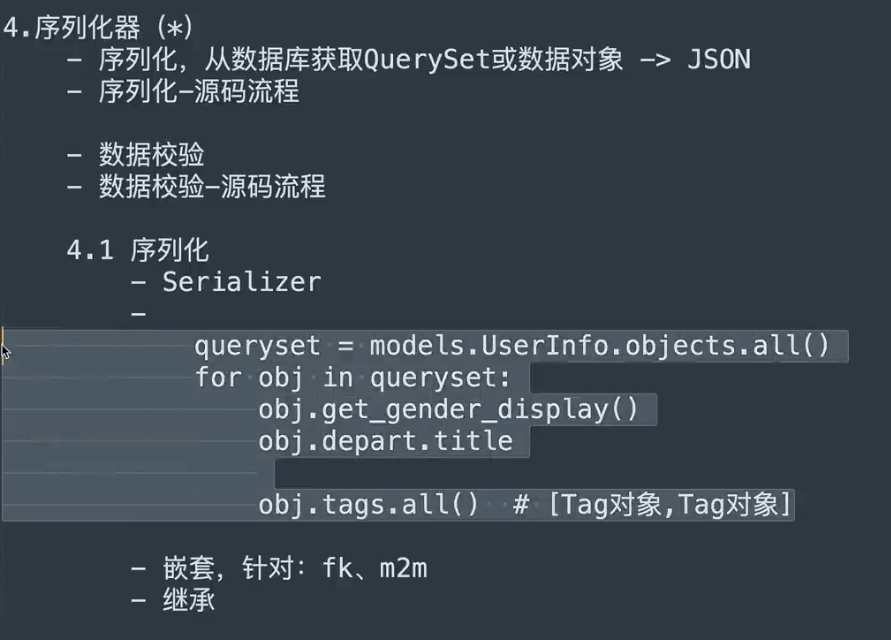
 1. 通过继承
1. 通过继承serializers.Serializer类创建序列化器,序列化器用于将数据序列化成json格式
2. 通过设定序列化器对象的many字段为Ture,可以实现序列化器序列化querySet(多个数据)
3. serializers.ModelSerializer类比Django中form和ModelForm的功能,用于快速创建序列化器,同时也可以和modelForm一样,对字段进行自定义gender_text=serializers.CharField(source="get_gender_display")
- 通过source字段指定字段来源,可以是字段也可以是函数,外键可以通过参数.字段名来跨表获取对应值
- 通过format字段指定字段格式,如format="%Y-%m-%d %H:%M:%S"
4. 通过MyFun = serializers.SerializerMethodField()自定义方法。通过get_MyFun()方法获取返回值,其中的obj对象即为这个序列化器定义的类对象。通过它可以实现多对多关系字段的获取等自定义操作
5. 嵌套(类里面的字段是另一个序列化的类),针对:fk、m2m、
6. 继承 序列化器类可以单独使用,也可以继承其他的序列化器类
7. 序列化源码流程
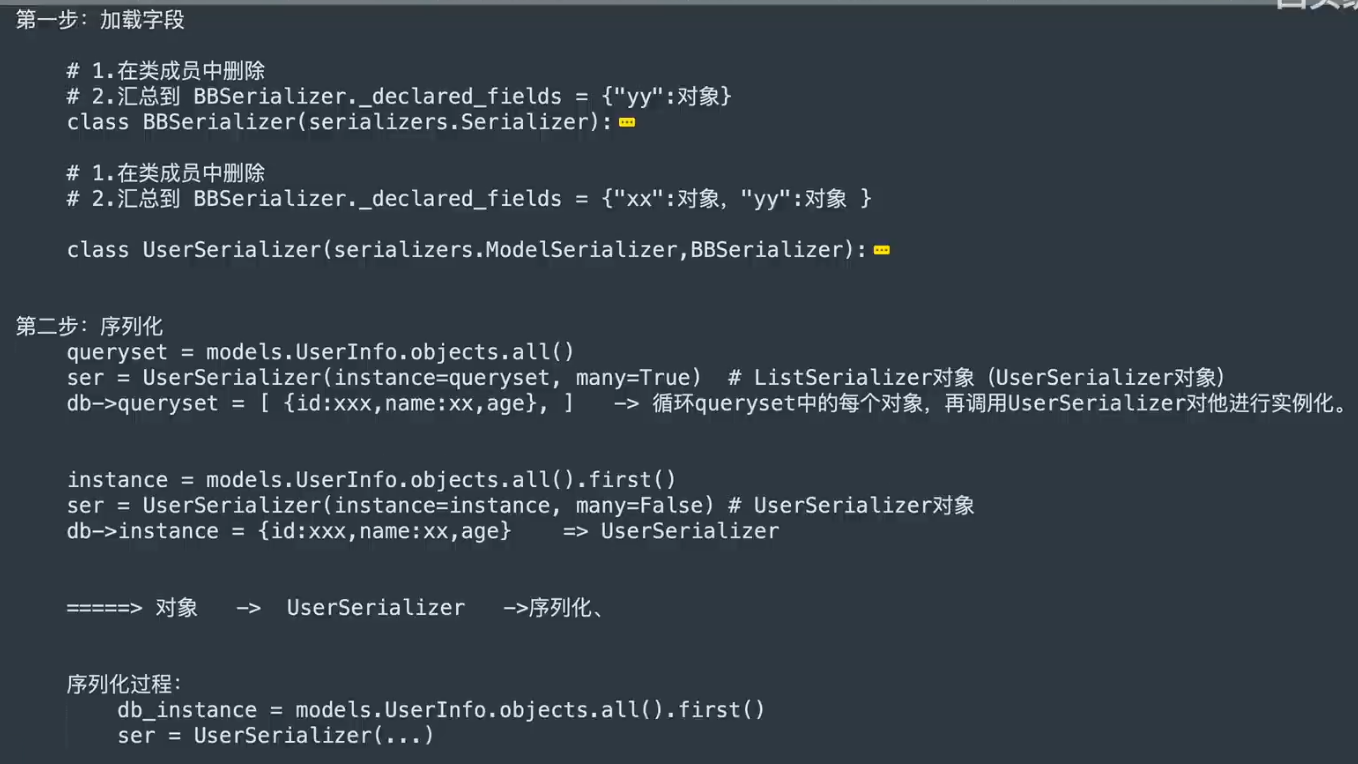
 - 类创建时,类的参数要先于类进行创建,因为类要通过
- 类创建时,类的参数要先于类进行创建,因为类要通过MyType()进行创建,类的参数要传入MyType()中
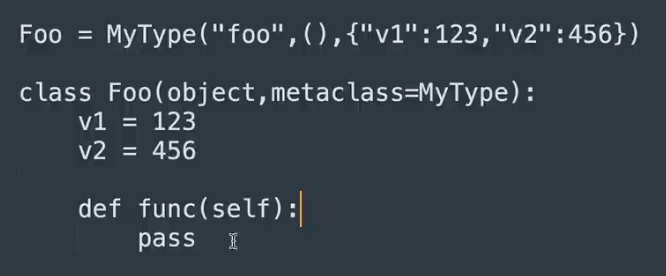 -
- Field类中的creation_counter字段的作用是让后续开发时,根据编写顺序来定义后续源码中各个字段处理顺序。
- 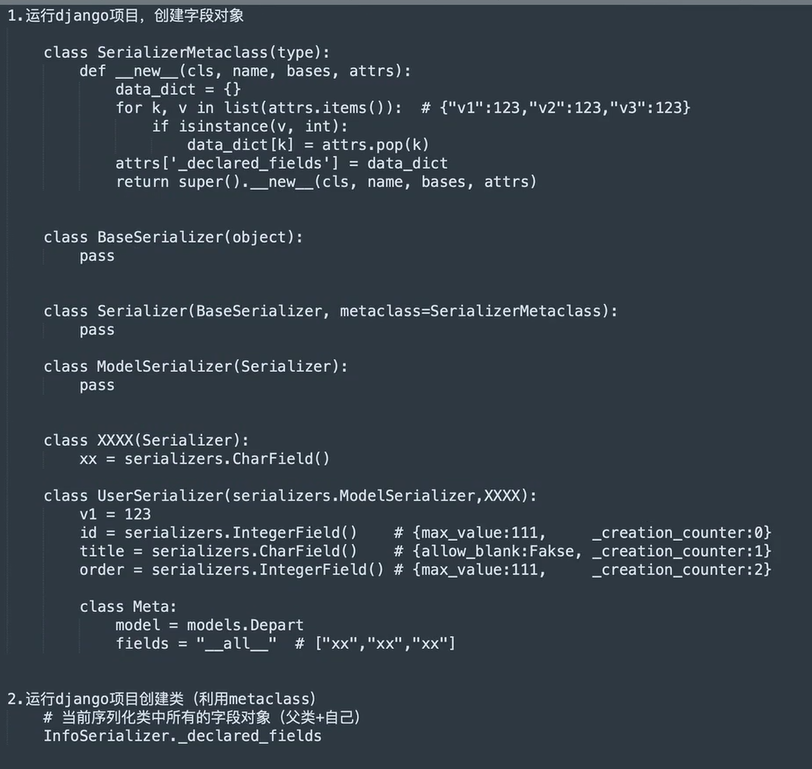 -
- 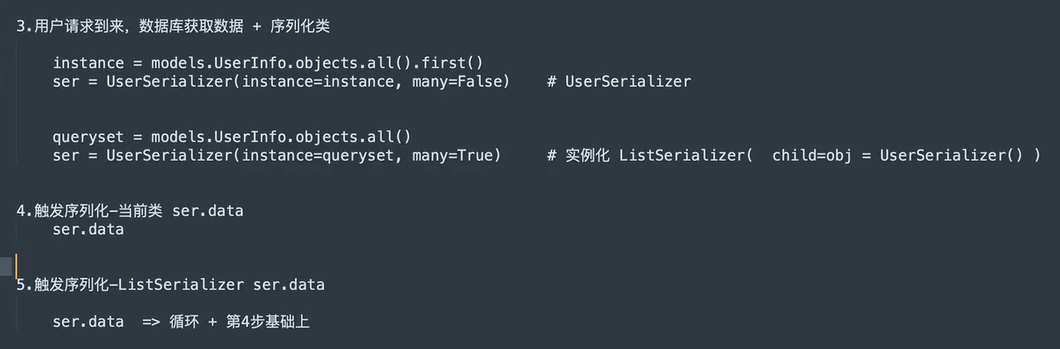 8. 数据校验
-
8. 数据校验
-  -
- 
day15 drf下篇

- 序列化器
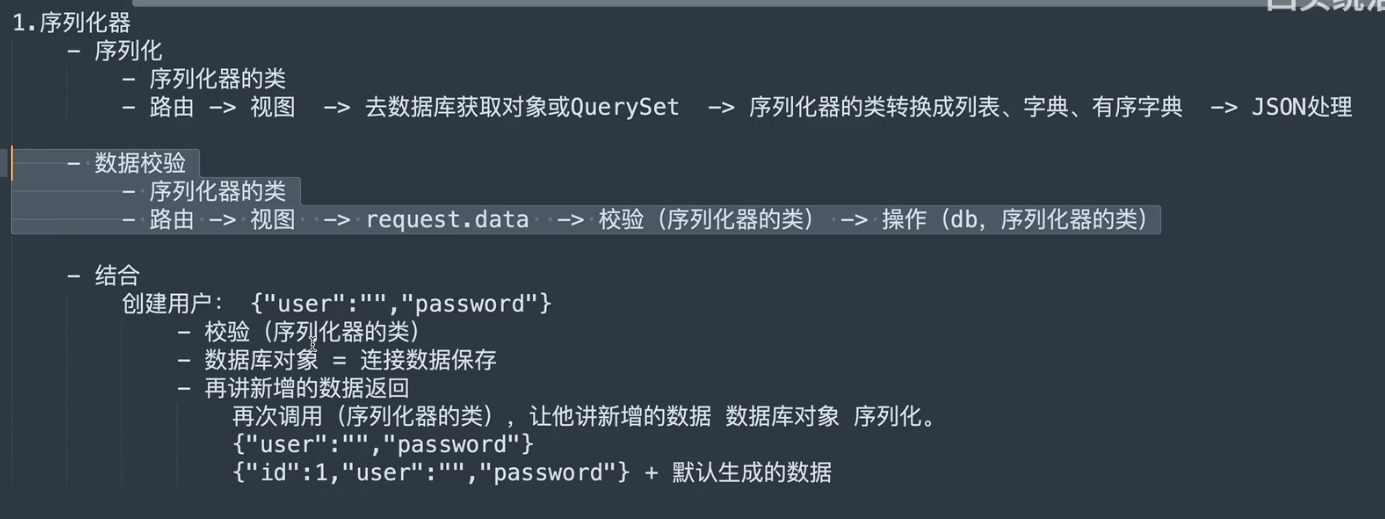

- 序列化
- 数据校验
### serializer
1. 创建序列化对象时,序列化使用
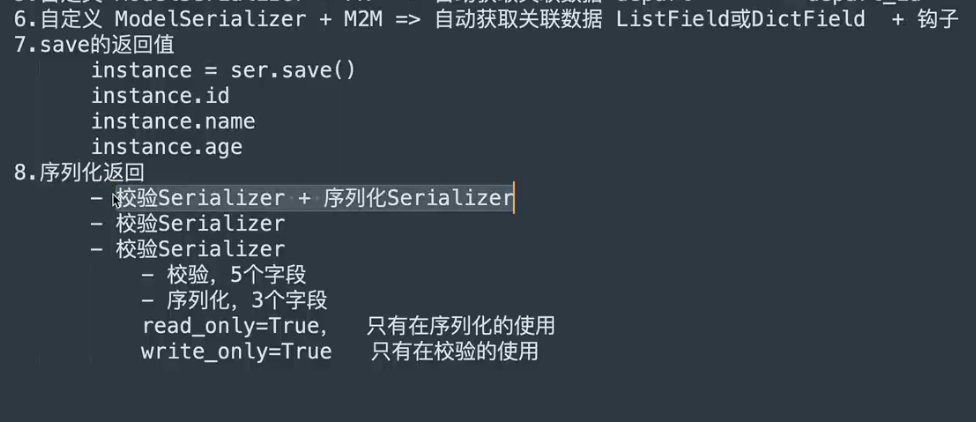
serializer = MySerializer(instance=obj),校验使用serializer = MySerializer(data=data)2. 基本校验、内置校验、正则校验、钩子校验-适用于复杂校验 3. 序列化的钩子方法使用get_xxx()。校验的钩子方法使用validate_xxx(), 4. 校验所有字段用validate()方法,其在调用完单个字段的校验后,会自动调用validate()方法。 5. 全局校验适用于一些单个字段校验通过了,但是额外附加条件不通过的情况。这种校验也可以在业务代码中做 6. 通过在settings中设置non_field_errors_key可以修改全局报错的key ### modelSerializer 1. 通过在meta类中配置extra_kwargs来添加额外校验 2. 帮助我们将数据直接保存到数据库可能会出现校验通过但是不能保存的情况 1. 传过来的数据少于数据库要求的数据。`.save()`方法中可以传额外的参数,会一同保存到数据库中 2. 传过来的数据多于数据库要求的数据。先进行`ser.validated_data.pop("字段名")`剔除额外参数,再`save` 3. FK和M2M 1. 如果使用FK,会自动判断该键是否在对应表中存在,不仅做校验还将外键转换为对象, 2. M2M也会进行这些转换,区别是转换为对象列表 3. 对于FK的id的问题,数据库中在外键的位置存的是xxx_id,如果发请求直接传xxx_id,会报错,因为序列化器中没有定义xxx_id的转换方式,要是实在想传可以自己定义该字段 4. 如果想自己处理M2M,可以自定义字段,传列表过来,序列化用`ListField()`,用钩子方法将数据转化为对象 4. 同时校验和序列化 1. `save()`方法具有返回值,会返回一个对象,可以用来做校验,序列化器用的是哪张表,返回值就是哪张表的对象,如果返回值是None,说明校验失败,不会进行序列化 2. 校验和序列化可以使用不同的`Serializer` 1. 当使用相同的`Serilizer`同时进行校验和序列化时,直接调他的data就可以返回数据 3. 序列化器里的字段可以加参数`read_only=True`只读,只有在序列化时才使用 `write_only=True`只写,只有在校验的时候才使用 1. 通过只读、只写可以控制传参字段、返回值字段 2. 通过钩子方法可以达到同样效果 3. 通过序列化器的嵌套也可以达到该效果,比如M2M,把id传给内层序列化器,返回所有信息需求
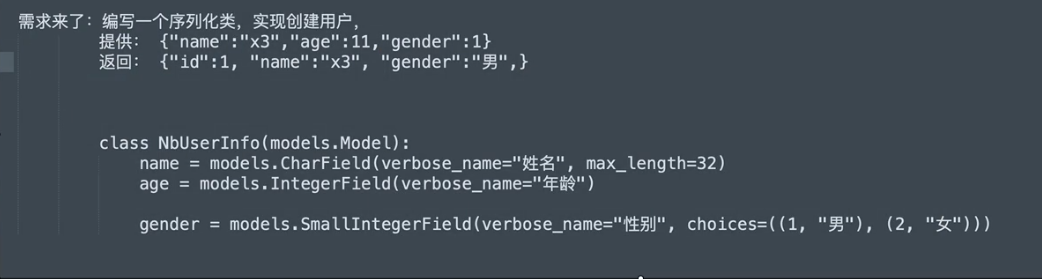
实现方法1
- 因为使用
serializers.SerializerMethodField()自定义方法时,需要自己定义一个字段,用钩子方法来处理。在字段内部限制了read_only=True,所以没有办法通过请求时输入这个字段的值来实现【无法输入】 - 通过
serializers.CharField(source="get_gender_display")添加source,实现自动映射。但是需求要求输入和输出的字段名一致,这会导致无法自动映射【无法映射】 - 所以通过继承field,自定义方法来实现
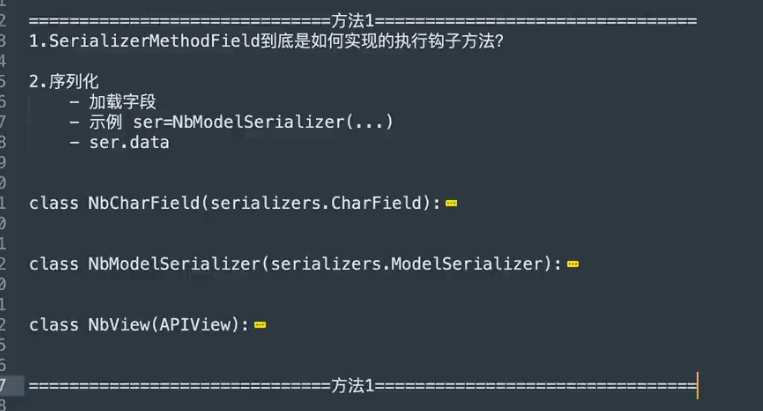
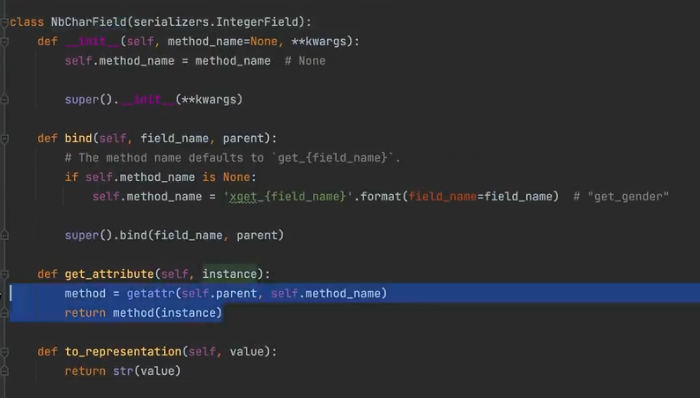 #### 实现方法2(更好 )
#### 实现方法2(更好 ) - 重写
to_representation()方法, 实现对字段的处理 - 可以自己写一个类实现这个方法,用的话直接继承就行
- 继承时,写在前面的优先
- 可以继承多个类
案例:博客系统
- 因为使用

功能
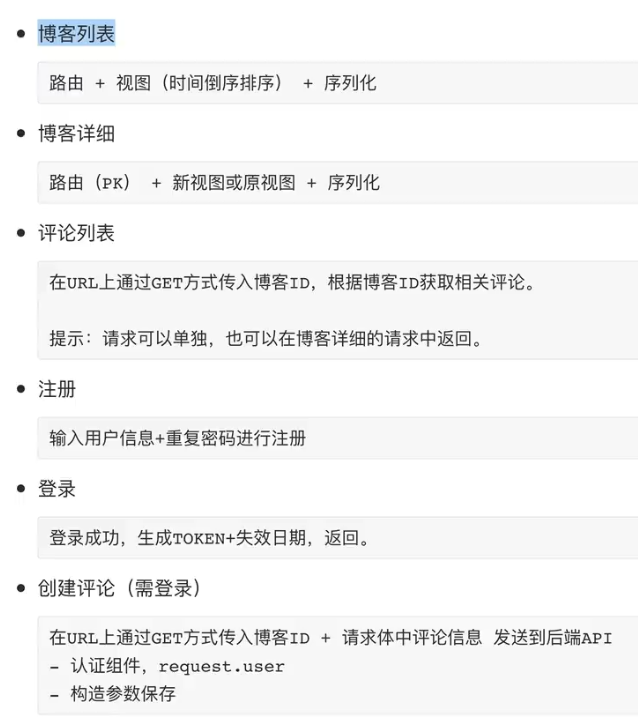

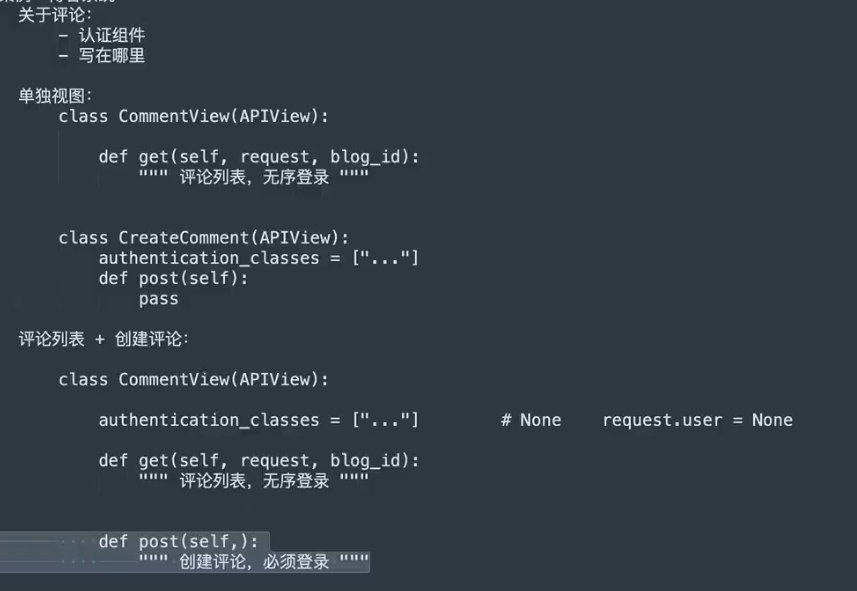
课程中的闪光点
- 权限校验的自定义。由且的关系变为或
- 序列化与映射的二合一,传入传出同名字段冲突问题的解决
案例二:分页
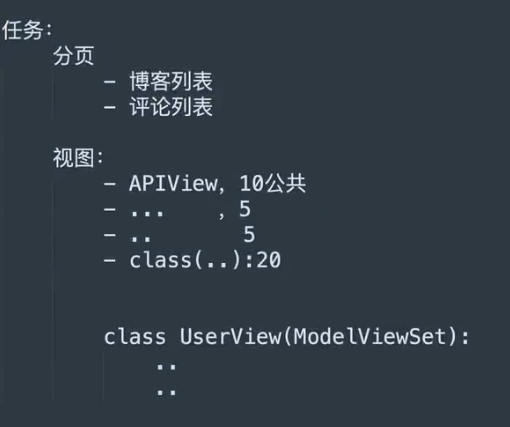
一些零碎的点
-
创建django项目时,通过指定目录可以将项目创建在当前目录而不是当前目录的子目录
在表示相对路径中,单点表示当前目录,双点表示上一级目录,反斜杠“/”表示分隔目录; 相对路径特殊符号有以下几种表示意义:
-
以“./”开头,代表当前目录和文件目录在同一个目录里,“./”也可以省略不写!
-
以"../"开头:向上走一级,代表目标文件在当前文件所在的上一级目录;
-
以"../../"开头:向上走两级,代表父级的父级目录,也就是上上级目录,再说明白点,就是上一级目录的上一级目录
-
以"/”开头,代表根目录
-
-
应用drf时首先要在settings.py中注册。因为可能要用到它的模板和静态文件。django会去已经注册了的app中寻找
- oop:面向对象
-
列表推导式 列表推导式是一种简洁的方式来创建新列表。它的语法如下:
[expression for item in iterable if condition][可迭代 if 条件中项目的表达式]
其中expression是一个用于生成新列表元素的表达式,item是可迭代对象中的每个元素,iterable是可迭代对象,condition是一个可选的用于过滤元素的条件。
下面是一些示例:
创建一个包含1到10的平方数的列表:
squares = [x**2 for x in range(1, 11)]
过滤一个列表, 只保留偶数:
```python
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
even_numbers = [x for x in numbers if x % 2 == 0]
```
根据一个字符串列表创建一个新列表,包含每个字符串的长度:
```python
strings = ['hello', 'world', 'python']
lengths = [len(s) for s in strings]
```
使用嵌套的循环创建一个平面坐标的列表:
coordinates = [(x, y) for x in range(1, 3) for y in range(1, 3)]
使用条件语句进行条件赋值:
```python
numbers = [1, 2, 3, 4, 5, 6]
new_numbers = [x if x % 2 == 0 else -x for x in numbers]
```
这些只是列表推导式的一些示例,你可以根据自己的需求使用不同的表达式和条件来创建自己想要的新列表。
- 获取请求中的参数
python request.data#获取请求体中的参数 request.query_params#获取请求头中的参数 - 连接docker里的redis
- 创建容器时要记得映射端口,不然宿主机访问不到容器内部
docker run -d -p 6379:6379 --name redis_container redis创建容器的命令,关键在设置端口映射- 通过
docker exec -it <容器id或名称> /bin/bash进入容器并打开交互式终端
常见报错
-
Model class django.contrib.contenttypes.models.ContentType doesn't declare an explicit app_label and isn't in an application in INSTALLED_APPS. -
认证组件中的匿名用户导致了这个问题
- 当没找到用户时会执行
_not_authenticated方法。其中: ```python def _not_authenticated(self): """ Set authenticator, user & authtoken representing an unauthenticated request.Defaults are None, AnonymousUser & None. """ self._authenticator = None if api_settings.UNAUTHENTICATED_USER: self.user = api_settings.UNAUTHENTICATED_USER() else: self.user = None if api_settings.UNAUTHENTICATED_TOKEN: self.auth = api_settings.UNAUTHENTICATED_TOKEN() else: self.auth = None调用self.user = api_settings.UNAUTHENTICATED_USER()和self.auth = api_settings.UNAUTHENTICATED_TOKEN()```方法时会用到django中的一些组件,如果没有启用这些组件就会报错。 - 解决方案直接设置```UNAUTHENTICATED_USER```和```UNAUTHENTICATED_TOKEN```为空,这样就不会走到为真的分支里